Archive, Backup, Copy
A is for Archive, B is Backup, C is for Copy

Hedge’s aim has always been to offer Finder and Explorer uses a speedier and more reliable copy machine. However, a sizeable chunk of our users is using Hedge for archiving, data migrations, and other workflows.
To accommodate these pro workflows better, we’ve rewritten Canister’s Archiving engine to also work for simultaneous transfers and included it in Hedge as part of Checkpoint, our source integrity engine. Checkpoint now comes with two modes: Backup and Archive.
So, when to use Checkpoint, and then, which mode? Get ready for a deep (13 minute) dive into what backups and archives actually are.👇
Thesaurus Rex
Semantically, “copying data” is a mess: backup, archive, sync, synch (?), incremental backup, clone, mirroring, and of course, copy all have fluid definitions depending on the use case and user.
Many people, especially ones that never dabble with external storage, consider Time Machine a backup. To others, it definitely is not, as it lacks a mirror of the OS and is not bootable.
What a DIT refers to as a copy, can be an archive to a data center engineer. An incremental backup can be one that copies all new and changed files (like Hedge does), but for an IT pro, it’s about copying only the changed blocks, with deduplication (think Retrospect).
There are simply too many variations and assumptions for a level playing field. Let’s make this easier for everyone:
A-B-C, easy as 1–2–3…
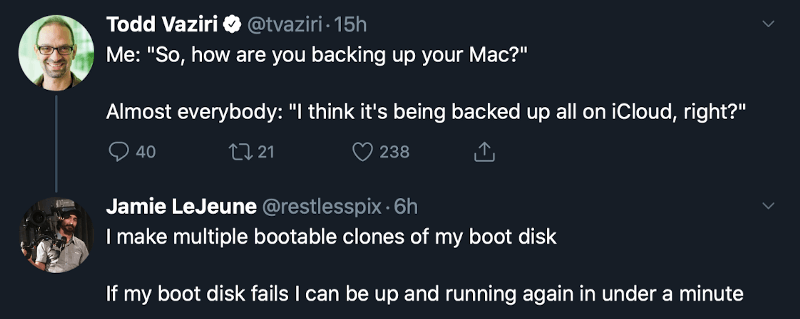
We propose you either have a copy, a backup, or an archive. The difference lies in what you intend to do with the data:
- Copy — a clone with the sole goal of making it possible to use it in a different location. Copies can be erased freely. If you happen to delete an original file, it’s convenient that there’s a copy somewhere, but it never was a requirement in the first place. It’s not a…
- Backup — a duplicate of the source meant for safekeeping. You’re expecting the source to not be available at some point in time. Backups ALWAYS exist in multiples. Remember the saying “if a file doesn’t exist in three places, it doesn’t exist”? That’s a backup because it always allows you to recover your data from at least somewhere. Backed up all your photos on a hard drive, and deleted them from your laptop? That’s not a backup; it’s an…
- Archive — a complete replacement of the source. An archive can be the sole copy, or one of many, as long as it by itself lets you recover all data in full, without having to resort to another archive. Archives can be a backup, but a backup is not an archive.
And sync? Sync is nothing more than an incremental copy.
How It’s Made
If you’d simultaneously mount a copy, a backup, and an archive of the same data, you’d get three identical drives. So what’s the fuss about anyway?
It’s about how they were made, and the only differentiator here is checksums. But wait — it’s not just about using checksums. Every copy mechanism uses checksums, even Finder. Having a checksum by itself isn’t useful. It’s about knowing how they were created: from the source.
For Archives, independence is its most important property: each archive on its own must be able to serve back 100% of the data. Therefore, its checksum regime is the most strict: checksums should always be made of the source, twice, to be sure it was read properly.
Example: a DIT offloads a card to a RAID drive, and erases the card. Even though many think RAID is a backup, it is not: even when in mirrored mode, both copies cannot be verified independently, and thus it’s a single archive.
A Backup’s strength lies in speed. Because they always exist in multiples, there’s a big speed gain to be had when created simultaneously. If drives are of comparable write speeds, with proper software, it should not take longer to create three than it does to create one. That’s a big plus, as backups are group animals.
Together, they can serve back 100% of the data — if a file on one backup gets corrupted, nothing is lost as there will be a duplicate in at least two more places. RAID controllers use a similar process to make sure files are recoverable through parity checks. Still, while RAID uses its “backups” continuously, a lot of people frown upon having to actually use a backup, as if it’s a dirty thing.
Backups are meant to be used. It’s why you made them in the first place: as a safety belt. Having a safety belt in your car while not using it doesn’t help you when you crash, and it’s the same with backups. Backups are a cost-effective way to know you can very quickly restore a file when something goes wrong with data that is in active duty. Having a second car back at home would be your archive – it takes time to recover, and it doesn’t help you immediately when crashing.
If the original is going to be deleted, Checkpoint should be used to make sure no bogus data is being stored. Even if you don’t plan on erasing the original, it’s still recommendable, but it does take some extra time.
For copies, source checksums are a nice-to-have. When created, they give you a snapshot that can be used in the future for reviewing, but in general, they are noise. It’s much faster to see if a file opens, and even if it does and some data is garbled, chances are it’s still pretty usable. Need to watch a quick screen recording, but there’s a purple line in it? It’s corrupted for sure, but not per se a problem if you don’t have to use it in an edit. Corruption does not have to be destructive per se. Speed and usability are key here: you need data fast, you don’t necessarily need an exact copy to reach your goal, and it’s equally fast to get back to the original in case something’s amiss.
A false sense of security
Most people, when asked about checksums, say that they need destination checksums, but that’s a too simplistic way to think about it.
The way destination checksums are in use in media production stems from a time where both hard drives and operating systems were pretty wonky, and they served a good purpose: to check for write errors. The cost of calculating them was huge due to CPU limitations, but the risk of losing data due to hardware issues very real, so the ends justified the means.
Nowadays, destinations checksums are nothing more than a Cover-Your-Ass instrument: with a checksum, people feel they have a way of proving data was copied correctly. It’s not only a very negative approach of working together, but most importantly, it creates a false sense of security — 99% of backups are made without source verification, and the source is by far the weakest part in the whole chain. It’s a SPOF, and because it’s part also of a chain, the SPOFs add up quickly: card, reader, interconnect, hub, cable, power supply. Destinations, on the other hand, often connect either directly to your computer or share a hub that, in the case of issues creates I/O failures that are caught by the OS. Much less moving parts on that side of the equation.
The failure rate of modern storage devices is so low that the chance of running into a write error is already near-zero. Even when you do run into one, it’s unitless — checksums cannot tell why something happened or how severe the error is, only that something is different than expected.
On top of that, all modern storage devices nowadays have buffers, caches, and even RAM, so it’s not even possible to conclude that an incorrect checksum means a thing. It’s only a flag saying you should investigate further. It’s also doesn’t prove anything: if I have a corrupted file with checksum X and you have a record of a checksum Y, without a source verification mechanism in use, there is no way of knowing if Y was made from a correct file. Maybe there was no correct file to begin with. The only conclusion we can draw is that there are now two checksums. That by itself is useless information.
With archives, destination checksums are vital, but with backups, destination verification is not that important, as an often-overlooked mechanism comes into play: entropy.
How I stopped worrying and love the backup
Imagine you have to simultaneously instruct 3 friends to construct 3 identical IKEA kitchens, and you only have the manual. They cannot talk to you, only listen, and do not know that others are building kitchens too. It’s pretty likely that at some point, an instruction gets misinterpreted.
One friend happens to be faster at building kitchens than the others, so to not slow everyone down, you’re going ahead and give him new instructions while others are still busy finishing a step. You’re busy keeping tabs on who’s doing what, so your instructions vary a bit over time – not every friend gets the same instruction, as you have to reread the manual before giving directions again.
You want to end up with three perfect kitchens, but verifying that each step was done properly takes a lot of time, and would keep you from giving new instructions. So, you decide to do so after construction. You wouldn’t know for sure each kitchen is without construction issues before retracing each building step, times three, but so be it.
That’s how the media industry is handling verification: it’s building three kitchens somewhat at the same time, without keeping tabs, only to check for completion afterward. If a kitchen is not 100% OK, it’s scrapped, and IKEA is called to deliver a new one. No questions asked.
But what if each builder is allowed to repeat your instructions after you so that the two of you agree on what to do? That would catch at least the lousiest instructions, wouldn’t it? On top of that, what if all your friends would be allowed to do that together, to make sure they’re on the same page as well? Delivering three identical kitchens suddenly doesn’t seem too far-fetched.
Still, assumptions will always be made, and not every kitchen turns out to be 100%. But the odds that all three friends fluked at the same step are suddenly reduced to nil, thanks to removing entropy.
Can we do even better? Sure we can: what if each friend would be allowed to share pictures of the result of each step with the others so they could adjust and repair on the fly without having to order a new kitchen? We call that V&R — verify and repair, and run continuously on each destination during and after Copy and Backup transfers, quite like how hardware RAID arrays work, never eating up precious bandwidth when you need it.
One more thing – The Case For Source Integrity: your friends compared their notes, fixed some loose ends, and are pretty confident that they got your instructions right. And indeed, they did. Hurray. But they didn’t deliver good kitchens. How come? It’s because you’re the weakest link, as you’ve never built this particular kitchen before. You are the SPOF.
The solution: an example kitchen for everyone to compare. Do not compare your kitchen to what you assume it should look like, but to an actual kitchen. That makes a lot more sense to build, then to hope for a 100% correct kitchen, built with only a manual.
Checkpoint 2.0
Still with me? Great 😁
It boils down to this: “are you doing a 1-source-to-1-destination transfer?”
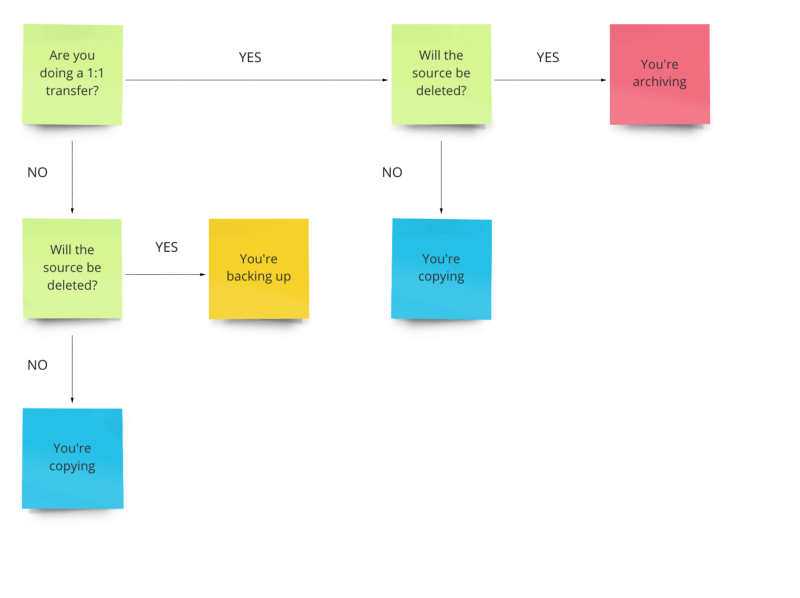
As always, we build technology in a generic way and then finetune it for media production. Checkpoint 2.0 comes with some nifty specializations:
- Early Warning Radar
When backing up, issues most often are caused by peripherals or heat, and thus likely to come in droves. That’s why transfers in Backup mode detect source inconsistencies as early as possible, and transfers immediately stop when an issue is detected, saving you time to investigate. Set up Connect for push notifications, and you won’t lose a minute.
In Archive mode, issues are more likely to be caused by a bad sector or a dropout in the network connection, so a transfer continues on error. This way, a large overnight transfer keeps running instead of halting at the first error, not wasting precious LAN bandwidth by having to rerun the full transfer during the day. When done, simply redo the transfer, and only the failed files will be transfered.
- Auto-Checkpoint
Many of you are using Hedge both on-set and in post-production. In post, you’re more likely to make copies, so you don’t need Checkpoint. That’s why it’s possible to define which source volumes should be using Checkpoint:

- 1:1 Detection
If Backup mode is enabled, but you’re doing a transfer to just one destination, Archive mode will automatically kick in for just this transfer. Comes in handy when you usually create backups but do that RAID offload workflow once in a while.
- Legacy Checksums
While XXHASH64BE has become the new checksum standard in pro video workflows, there is still a huge back catalog of media archives that use MD5. Besides that, chances are that if you’ve ever uploaded data to the cloud, a SHA1 checksum was used by the API driving the upload.
To make the transition to XXH easier for existing archives, Archive mode creates multiple checksums simultaneously. The transfer process itself will always use XXH, as it is simply the fastest algorithm, but with so many CPU cycles to burn nowadays, it’s cheap to also create MD5 and SHA1, for backward compatibility. These checksums are always created from source media, so there are effectively Hero Checksums.
- MHL Awareness
Say you do that 1:1 RAID transfer, and thus Archive is enabled, you now have Hero Checksums. It would be a shame if, when creating travel drives next, you would have to do another round of source integrity — you already have those checksums anyway. That’s why Hedge knows which MHLs are source verified, and utilizes those referenced checksums, instead of having to recalculate them. This allows you to create multiple Backups in the same amount of time it would take to create a single Copy.
MHLs are not just a list of checksums — they’re a way to save you a lot of time, as you only need to source verify once, preferably as early in the chain as possible.
- Transfer Sync
99% of the time, equally specced drives do not have identical speeds. This makes it harder for drives to keep up when they need to store a lot of data, especially when the files are of regular sizes, like photos or frame-based media. Remember that kitchen build? If one drive takes longer to interpret or execute instructions, some drives will need to ask for instructions again — leading to extra processing, and even additional partial source reads. So, Hedge actively manages supply and demand to all destinations, as we do in Canister. But how much time does transfer sync save? A lot.
We benchmarked Hedge against Shotput Pro and Silverstack Offload Manager. To eliminate from the equation a slow or underpowered source, we used the internal SSD of a 2014 Macbook Pro 15" — not the fastest source in the world, but not slow either: 500 MB/s read, on average. As destinations, we used a TB2 LaCie Rugged RAID and a TB2 LaCie Rugged SSD, with write speeds of respectively 200 MB/s and 160 MB/s. We on purpose used drives of unmatched speeds, to illustrate how much of an influence a synchronizing copy engine can have. We transferred 16GB of clips, a mix of frame and file-based footage, first to the Rugged RAID, and then to both drives. After each transfer, each drive was reformatted, and the Macbook Pro power-cycled.
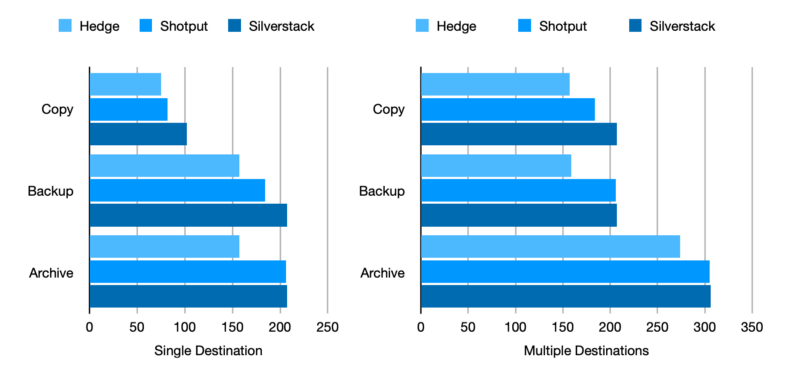
Shotput and Silverstack do not make a distinction between Backup and Archive, but both apps do have a faster and slower setting for checksum-based transfers. To us, it was a bit unclear what the ViV mode in Shotput exactly does, but it slows down the transfer and ends up being equally fast as Silverstack is in its slowest mode. So, for lack of a better comparison, we assume the faster setting to be somewhat similar to Hedge’s Backup mode, and the slower setting to be equal to Archive in terms of which checksums are being made and when.
We included Copy for comparison: both Shotput’s and Silverstack’s non-checksum modes do not create checksums, whereas running Hedge without enabling Checkpoint still gets you checksums, V&R, and of course transfer sync — the big differentiator.
Serverside Verification
We never build a feature without envisioning where we ideally would want to take it, even if that is out of reach. It’s the proverbial 10x feature. For destination checksums, we feel that’s serverside verification.
In an era where bandwidth defines workflows, and every storage device is effectively a full-fledged computer, it’s rather wasteful to be doing destination readbacks for verification, and thus occupying precious bandwidth — locally, or on a network. Each storage devices’ host processor is perfectly capable of serving back checksums, not unlike many web APIs already do by returning SHA1 checksums of data chunks.
Envision a world where each storage device would serve an API that would give you the checksum for a file, creating upon storage of that file. Right now, to check if a kitchen was installed properly, we’re going over to a customer’s house, walk in and out until we’ve created a copy of the kitchen outside on the sidewalk, check the copy for issues, and then OK the installation. Sounds silly, doesn’t it? Better to ask the end-user if their kitchen works as intended, after delivery.
The technology needed for this is not new at all. It’s just a matter of storage and NAS vendors to start thinking software-first. Software-defined storage, if you will. Who’s gonna lead the pack? We’re ready for it 💪
Available Immediately
Checkpoint 2.0 is included in Hedge 20.2 on the Mac and Windows: